


Identity Deathmatch: Unification vs. Integration
- Lauren Selby
- January 14, 2022
- Identity Data Fabric
- 9 MIN READ

Let’s get into it. If our goal is to reduce complexity and make identity data usable across the organization—to enhance security, drive better business decisions, and support ongoing change—what represents the best approach for doing that? Integration or Unification?
Much like the clay-animated celebrities in a deeply immature television show from the late 90’s, approaches to Identity & Access Management (IAM) must be made to fight to the death. Enter the cage, and let’s see which method survives scrutiny in this edition of Identity Deathmatch.
Integration
In one corner we have “integration”, a murky function that many players in the IAM world say is included in their solutions. What does that mean exactly? The definition varies vendor to vendor. It’s amorphous and unknowable. It’s a secret, you wouldn’t understand. It has something to do with consolidating identity; connectors play a key role; it may include some basic merging of user profiles where there is a common identifier handy, perhaps de-duplication, and probably a good deal of manual effort to make things work across different applications.
Integration is usually a lightweight approach that aggregates identity information for a specific use within a particular tool, at the application layer, for a specific purpose (think single-sign-on, multi-factor authentication or governance and administration). Even if the integration “process” removes duplicate accounts and normalizes data, the end result is still a siloed set of user information that can only be used for that specific use case. It’s a semi-manual process of aggregating identity data in a rigid and proprietary format specific to one system—and it may be only a subset of the user set you really want to integrate, and a very narrow definition of identity that leaves out important user information. The process for accomplishing this may vary—from Extract Transform Load (ETL) to connectors—but it all amounts to the creation of another static system, rather than an identity foundation that will serve multiple initiatives.
Applications can swap identity information with each other using federated access protocols like SAML and OIDC—but does that really count as identity integration? We can see that integration falls short in the long deployment times for rolling out initiatives like SSO or IGA. Why are these deployments so challenging? Often the roadblock is getting a unified feed of identity data to make the tool work as desired, and the challenge of getting at the identity data will often take significantly longer than expected. A typical issue we see organizations run into is that dispersed identity leads to failure for Identity Providers (IdP’s), since identifiers don’t always match across systems. The IdP can send your email along to the application you want to access—but what if you aren’t known by email there? Or you’re known by a different email? Maybe this application knows you by a proprietary user name instead? The IdP isn’t the component responsible for sorting out the difference, finding the correct identity attribute, or resolving the identity collision. So, whose job IS that? (It’s ours).
“Integration” is usually done at the application layer and enables key functions like SSO, but it doesn’t go deep enough to address the quality of the data feed that drives the success of the tool. If you want to add operational agility for SSO and all other initiatives—it all comes back to the DATA. Unreliable access to data, inconsistent data, disconnected data. This is your roadblock. And it’s exposing your organization to unnecessary complexity, inefficiency, and security risks—because access systems and tools are only as good as the data that feeds it.
Many IAM vendors are doing enough integration to suit their own purposes and perform their core tasks, but integrating identity data is not their main goal. That is a bit backwards. If I’m trying to “integrate” identity, why would I task my SSO platform with it, or even my Identity Governance & Administration (IGA) solution, when those two barely talk to each other? How can I create an integrated, seamless IAM infrastructure when tools don’t play nicely together or share data feeds? In sum, integration is a tactical approach in a strategic world.
Unification
Which brings us to our second contender, Unification. Unification is the end-to-end process of taking distributed identity data from all sources to build an identity foundation—a rich data set containing all user information that can be quickly and infinitely changed to represent identity according to any requirements. The goal is to take a core asset for organizations that is not being optimally leveraged—identity data—and transform it into a reusable resource for the entire organization, across many initiatives.
The crucial first step to unification is understanding where enterprise data is coming from, how it’s being used, and then making thoughtful, strategic choices about how it should be used. You need to identify, connect, correlate and contextualize identity data from all systems (including that legacy directory that you’re scared to touch), and make it available across your entire infrastructure—using the insights from this contextual data to improve security, efficiency, and ultimately to be a resource to the business.
At a high level, our approach is all about laying the identity foundation, by breaking down silos to harness the value of identity data that today is spread across a variety of non-interoperable systems. You can’t adequately protect a system of applications if you don’t have a clear picture of what’s really enforced at the level of each application, what’s available to be enforced, and how all your applications are interrelated. There is a missed opportunity when you’re not able to surface and leverage the relationships within the data (just think, do you have a global view of everyone who left your company last week? Everyone who has recently changed roles?). Establishing reliable identification of each user, and connecting accounts to all related data points (such as, what is the user’s risk score? what are their entitlements?), closes the gaps on what is crucial to know about your users. And that is where Identity Unification comes in.
The best approach to handle identity sprawl in today’s increasingly complex organizations is to implement an intelligent identity layer that decouples applications from the underlying infrastructure—making a flexible identity source that is re-usable across platforms and services and enables interoperability at the data layer. This contrasts with solutions that coordinate identity integration at the application layer, which tends to create more identity silos rather than truly “integrate.”
Identity Unification is a process that logically brings together identity data from all sources and protocols, to build a reliable identity resource that is infinitely flexible and consumable by anything, anywhere, anytime.
Using Unification to Build an Identity Data Fabric
Unification is accomplished with an Identity Data Fabric, an architectural component knitting together dissimilar and distributed data stores to make “getting to the data” easier. Identity must work across a number of contexts, which is what the fabric architecture is all about: making identity ubiquitously available in the manner most relevant to each consumer. No offense, but this is impossible to do with integration at the application layer.
To build your organization’s Identity Data Fabric, you need a platform that virtualizes identity data out of existing sources (on-premise and cloud directories, databases, applications), unifies it, and makes it available via the right interface.
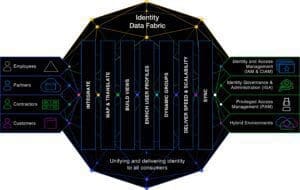
Let’s take a walk through the key functions required to unify identity, and how an Identity Data Fabric performs them—for the purpose of supporting the overall Identity Fabric (for more about the Identity Data Fabric, and the difference between that and the more widely-known Identity Fabric, please see my wonderful colleague and IRL friend Heather’s post on the topic here).
Integrate: Just the Beginning
You’ll notice the first step in the Unification process is Integration! Plot twist. Integrating is actually key to this whole thing, but it’s just the first step in the overall Unification process, and it has to be done Intelligently, with a capital I. A critical function is an automated but sophisticated process that can determine which digital identities represent the same entity (human or non-human), and how to handle it when the same identity shows up in various forms across systems.
Some questions to ask yourself when you’re lying awake at night thinking about your identity environment: What criteria or common identifier can be used to link an identity across all systems in your infrastructure? If there is no global identifier for establishing a connection, do you have a method for implementing a series of rules that can identify the same-users? When there are many same-users with different accounts spread across those sources, how is that managed? What if that same-user has multiple values for the same attribute—what if they are CONFLICTING across different sources and causing identity “collisions” at the application layer? Then what are you going to do???
This is not a problem that a series of connectors can solve. Managing this level of detail is best left to a specialized identity data unification layer.
Mapping and Translation
Building cross-platform interoperability means you need the ability to transform different data representations to meet varied consumer requirements. This is key for enabling interoperability—systems that don’t speak the same language need an interpreter; doing this translation at the data layer is the best option.
Let me give an example. You’re maintaining a legacy LDAP directory because critical applications rely on it, but you also have applications running in Azure. Many users need access to both sets of applications, and maintaining their account information across the on-premise and cloud directories is a pain but still has to happen. One of the challenges is that the data structure is different—in the LDAP a user’s location is stored as: “countryName= United States of America,” but that needs to be transformed for synchronization to and from the cloud system. Azure AD requires the value for this attribute to conform to a two-letter country code format (in this example, “usageLocation=US”). Keeping this information in sync across the different systems requires remapping on the attribute name and a computation for the value. Creating this single connection may be annoying but not a terrible burden, until you realize you have ten legacy directories and you’ll be running into this same issue with other cloud directories and new tools and platforms over and over… forever.
![]()
The fix is an intelligent identity platform that centrally manages transformation. This delivers efficiency of scale—you avoid having to customize a solution for every new project, new application, etc. into eternity. Configure, don’t customize.
Build Views
Unlocking the value of identity data means delivering access to that data securely and in the format, structure, and protocol that each consumer expects. To that end, an Identity Data Fabric helps you design views that meet various requirements, leveraging model-driven virtualization to tailor what each application “sees.” Decoupling applications from storage with a virtual abstraction layer lets you flexibly adapt identity data to meet different needs and make changes without causing disruption.
Enrich User Profiles
We can’t overstate the value of the Global Profile: a complete entry for each individual with data coming from multiple systems consolidated into one access point. The global profile enables modern security models like Zero Trust Architecture, by bringing together identity data from multiple endpoints—so fine-grained access solutions have all the information they need to enforce policies.
Dynamic Groups
Groups are traditionally based on a static label assignment to a list of given identities. When new identities are added, group memberships must be manually maintained. This creates additional work for system administrators, and leaves room for error that could put your security at risk should access be incorrectly granted or maintained. An Identity Data Fabric rationalizes existing groups and offers an upgrade from static to dynamic groups, massively simplifying administration while adding granularity to your access model.
Deliver Speed and Scalability
Given that our platform acts as a central information point for making real time access decisions (authentication, authorization), it has to be performant. Delivering reliable access, fast, to data spread across many disparate endpoints necessitates heavy-duty scalability based on the latest in storage technology. Enough said because I’m overrunning my target word count, but learn more about how we scale here.
Synchronization
Finally, synchronization ensures that data is consistent and up to date across the identity infrastructure.
Integration and Unification: Better Together
I was only kidding about the Deathmatch stuff. Integration is an important capability; it exists symbiotically with our platform—but I hope to make clear that integration alone doesn’t scale as a solution when you have complexity in your infrastructure. That’s a job for Unification.
RadiantOne is here to weave all these elements together, to enable the multifaceted IAM system through unified identity data. We want to avoid the piecemeal approach by laying the identity foundation—easily threading in more advanced solutions (think Attribute Based Access Control, Zero Trust Architecture, etc.) and new technologies as organizations want to adopt them.
Let’s Be Friends
There is already an awareness of the need for integration in our space. We see this in the move towards the fabric architecture overall, and with standard protocols at the application layer, like OIDC and SAML, for federating access via Identity Providers. We see it with orchestrators, managing security policies across clouds and IAM systems. Clearly, our customers want the ability to assemble solutions that, together, add up to more than the sum of their parts.
So how do we get there? The emerging fabric pattern offers a way to establish interoperability seamlessly. An Identity Data Fabric establishes a common framework for easily integrating solutions. Unifying identity at the data layer, versus integrating for individual solutions—means we can avoid making a series of point-to-point connections in redundant, wasted effort.
That’s why RadiantOne is deployed to do the toughest identity unification work, helping organizations to build a trusted identity foundation that speeds project after project.
Identity Data is the Cornerstone of a Zero Trust/Zero Friction Approach
As IT sprawl accelerates, larger attack surfaces emerge and identity information is spread across a complex web of legacy, hybrid and multi cloud systems. How can you ensure that only authorized and approved subjects can access the proper resources without putting all the work on the end-user?
-
October 21, 2021

-
78 minutes

Explore more



Subscribe to receive blog updates
Don’t miss the latest conversations and innovations from Radiant Logic, delivered straight to your in-box.