Are Data Silos Your Key to Better Cybersecurity?

From the largest enterprises to the smallest local businesses, every company has a data silo—or, more likely, many silos. Each one can slow down how your company works, but most importantly today, it affects how these organizations deliver cybersecurity.
Silos are both a sunk cost and a potential goldmine, full of rich attributes that could drive deeper insights and smarter security across your organization—if you can access them efficiently. This has been a real pain point, especially for large, complex companies, due to the widespread nature of the silos and the time, effort, and expense of trying to hard-code a vulnerable one-time-use connection. Add in any legacy technology and a far-flung remote workforce, and it’s a nightmare for security.
But instead of blowing up the silos and moving all that disparate data to a central repository, there’s a better option. One that lets you keep all your company’s authoritative repositories—which are perfectly purpose-built for the job they do—while making them easier to access, unify, and secure within your tech stack.
It’s called an identity data fabric, and it’s the secret to stronger, more flexible cybersecurity. An identity data fabric unifies your identity data across diverse stores in a way that makes it consumable by any application or system in your company, whether that’s legacy or modern, on-prem or cloud.
Your security team can use the identity data fabric to create a security strategy that’s unique to your needs, scales across the organization, and instills confidence in your security posture. And that confidence is something that many company executives can’t count on, as we see from this study where nearly 90% of IT leaders were uncertain about their company’s IT security.
Let’s take a closer look at data silos and how an identity data fabric platform can help you increase your cybersecurity posture and give everyone more confidence in IT security.
The origins of data silos
Data silos are defined as a repository of data controlled by one department, team, or business unit that’s isolated from the rest of the company. The data is usually stored in standalone systems like LDAP directories, Active Directory (AD) directories, web service APIs, REST APIs, data warehouses, and applications.
These silos tend to spring up parallel to organizational structures, mirroring the growth and evolution of teams and workflows. Most arise naturally because each team or business unit operates independently. For example, your company may have information about a single customer in three different areas:
- Marketing may have contextual information on a customer, such as their engagement level before purchasing.
- Sales may have detailed information about various contacts with the same customer, which they use to set up demo calls or other sales-enablement activities.
- Customer support may have information about that customer after they finally purchase, such as their recent questions for help or what onboarding training they accessed.
Each department has its own goals, priorities, and budgets. Management doesn’t always feel the need to consult with the rest of the organization, including IT and cybersecurity teams, making it difficult to strategize ways to create fewer silos–or better connect the data contained with other sources of information to drive more informed decisions.
Teams are adding to their array of legacy systems with new applications, cloud services, and even edge computing (Internet of Things, or IoT) devices. Each one generates new identity data and stores it in a separate part of the ecosystem, often outside of an organization’s network. And silos lead to more silos, where a single silo for a team or legacy application can grow by three to five times as silos. And that’s bad news for companies looking to create more collaborative, data-driven organizations.
Data silos create barriers to data sharing and collaboration across the organization. When key data is stored across diverse repositories using disparate protocols, data is frequently duplicated or conflicting, with no easy way to know which cell number or user address is correct or authoritative. Without a higher-level view of all the data across these disparate silos, business leaders can’t view a transparent overarching view of company data to drive more informed decisions. The disconnect between teams, tech usage, and data location also introduces security risks to the broader corporate systems.
Why are data silos a problem for cybersecurity?
Siloed data is a major cybersecurity risk. Each new system, application, or cloud service generates new identity data. But this data is rarely mapped or aligned to existing security frameworks, making it challenging for companies to enforce identity management and cybersecurity policies using all the intelligence it has on its users and user types.
You can’t authenticate what you don’t know about
Security teams often struggle with data silos because of the challenge of authenticating and authorizing users across these isolated systems. There are too many systems for security teams to manage—and they might not be aware of every source of meaningful security attributes. Each application and system may have differing levels of identity and data security, as well. Unless the security team is aware of the system and knows about its security features, it can’t be sure it meets its security requirements.
The data’s geographic location can be a problem
Increasingly stringent global data privacy laws and new industry data security standards are also complicating the security picture. Companies must be aware of what data they have, where it’s stored, and how it’s used before designing the proper privacy strategy. For example, some applications hold customer data while others hold employee data. And each has its own governance rules and regulations that must be considered in the data security strategy.
There’s too much data to deal with effectively
With companies using an average of 1295 different cloud services alone, it would be a lot of work for IT teams to identify all the data silos, much less audit existing processes and structures and figure out a better way to secure the data, efficiently and securely. Not to mention trying to wrest the data out of the hands of each team or business unit, who feel deep ownership over that data and may be unwilling to relinquish their autonomy or authority.
But there’s actually a way to deliver better company security and greater user insights with your data silos. Yes, seriously.
Using data silos to unlock better enterprise security
The secret to better cybersecurity for your systems is to keep the data silos and use an identity data fabric to unify all this disparate data. RadiantOne Intelligent Identity Data Platform abstracts and transforms identity data across silos without the need to laboriously consolidate or decommission them. It handles decentralized data easily and securely, allowing you to create complete global profiles for users no matter where or how all this diverse data is stored.
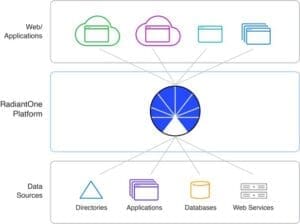
The identity data fabric “sits” between the data silos and the applications or systems that use the data. It unifies identity data across diverse protocols, identifies contextual relationships within your data, and makes it available via multiple protocols (such as LDAP, SQL, and web service APIs ) quickly and securely. Companies can use the identity data fabric to securely harness their existing identity data while seamlessly reducing friction for data consumers across your organization, allowing them to quickly view and search global user profiles to deliver enhanced security, build more targeted offerings, and enrich user experiences.
Be sure to continue the discussion in our next post!



